

There are not many things in digitalisation that are more discussed by all levels in a company including (and especially) the management. At the same time, discussions are vague, and real understanding of the topic and its practical implications is sometimes very limited: I am talking about data quality.
While it is very important to acknowledge the importance of data quality in general, most discussions stay on the surface and sometimes miss the practical point. All digitalisation consultants have and sell great frameworks to achieve perfect data quality within an organisation, books and articles are written on every aspect of the big concept of data quality.
I think, the generally perfect data quality does not exist. Even if it did, it would be economically infeasible, because the efforts to achieve it would be overwhelming and you could never motivate an organisation to do it.
I am proposing a very simple approach: Data quality is “fitness for purpose”.
What’s not helpful
“Our data is not good, we need to achieve ~better data quality~ before we can do anything with it.”, is an often heard sentence in digitalisation/data initiatives, and it’s not helpful.
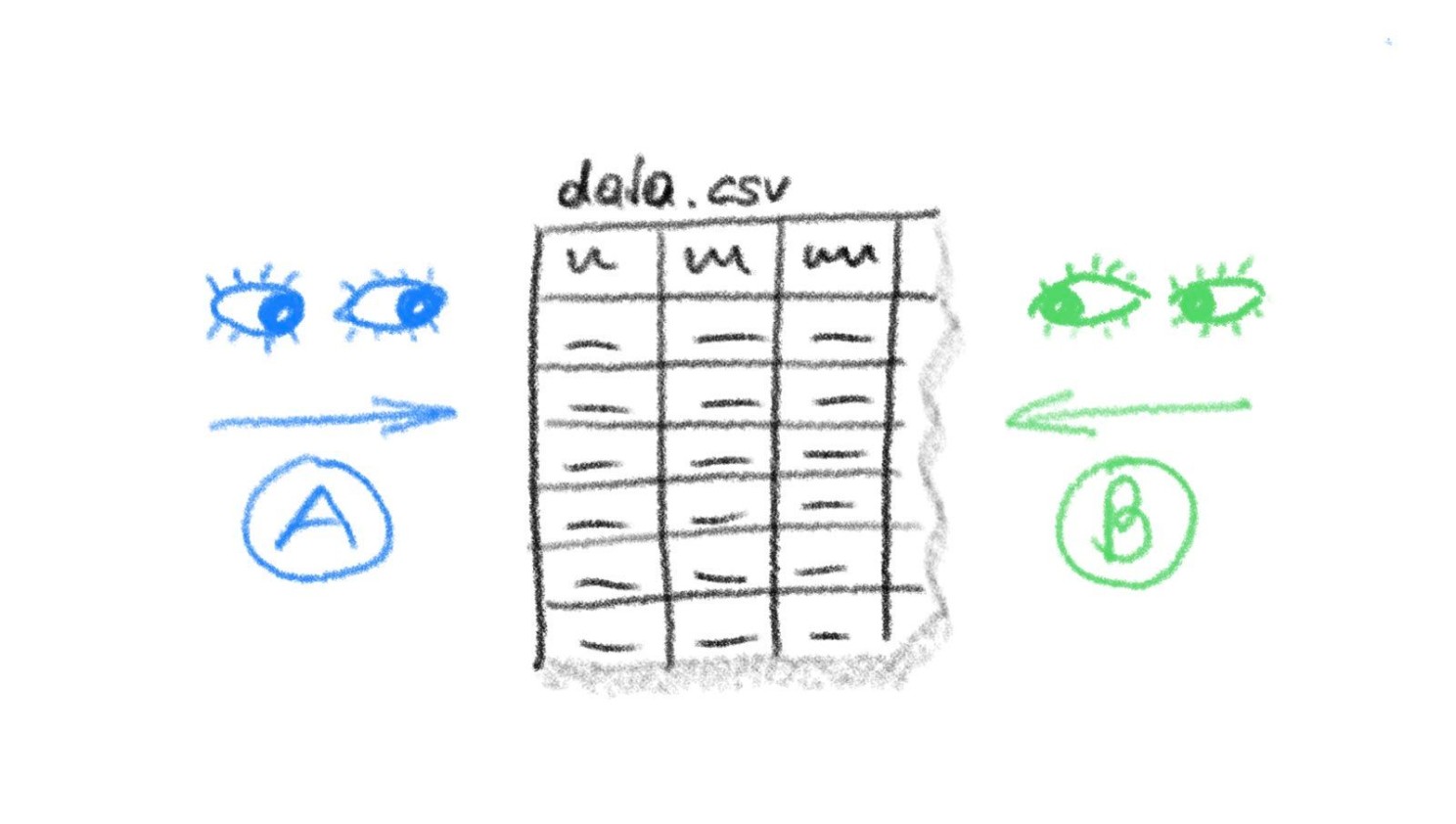
A dataset’s data quality must be assessed in the context of its use. One dataset might be perfectly suitable for purpose A, and at the same time useless for purpose B.
In a simple example, let’s say the data set contains data from a machine like sensor values and produced materials: In A you would like to analyse how different materials result in different forces and wear to the machine. In B you would like to monitor sensor value deviations that can predict sensor damages. Two very different things that can mean quite different requirements to the dataset.
Besides some very basic universal quality criteria, one always needs to look at a dataset through the eyes of the actual use in order to judge (and consequently optimize continuously) its data quality.
What’s helpful
The practical approach to data quality is to actively work with your data. Be very specific about your use case and define & assess precise criteria accordingly. Start your use case small and make first trials with your data, identify and demonstrate specific shortcomings of your data and improve in small iterations. Take it step by step and be ready to keep up these continuous data quality improvement cycles.
I am convinced that only by doing this use case oriented approach can you motivate people to jointly work with you on the data quality - ideally by improving it at the source.
So, next time when someone tells you about bad data quality, ask him what he actually wants to do with the data. Or ask her by what criteria - in the context of her use case - she comes to this conclusion. If this cannot be answered, the discussion remains an academic or philosophic one.
If you would like to read more of my blog, check out the list of posts here!